Статията се спира на проблема с ефективното използване на кеш паметта
при програмирането на модерни микропроцесори. Кратък експеримент показва
значението на кеша за ускоряване на изпълнението на програмния код. Представена
е и кратка рецепта как да държим процесора си добре нахранен.
Глад за инструкции
През последните години сме свидетели на постепенно изоставане на работната
памет спрямо темповете на развитие на микропроцесорните технологии. Докато
работата на микропроцесорите (честота и брой на изпълняваните инструкции
за цикъл) се подобрява средно с около 40% годишно от 1985г. насам, времето
за достъп до работната памет изостава със средно годишно подобрение от
само 9%. Въпреки, че сега се търси нов заместник на синхронния DRAM, най-вероятно
тенденцията на изоставане ще се запази.
За пълноценната работа на микропроцесора се изисква той да бъде постоянно
захранван с инструкции от работната памет. Паметта обаче трудно насмогва
на неговия непрестанен апетит, тъй като работи няколко пъти по-бавно от
него и всеки достъп до нея трае десетки микропроцесорни цикъла. Ето защо
изоставането на работната памет оказва влияние върху изпълнението на програмите
и въобще скоростта на цялата система.
Това явление може да се нарече истински "глад за инструкции", а той
както беше споменато ще нараства с всяко ново поколение микропроцесори.
Микропроцесорът си купува хладилник и фризер
Най-популярното решение е въвеждането на своебразен "мост" между микропроцесора
и работната памет. "Мостът" представлява ограничена по размер, но бърза
буферна памет наричана кеш (от англ. cache - сигурно място за скриване
или съхранение на неща).
За пръв път се заговаря за кеш паметта през 1965г. в Англия. След публикуването
на идеята IBM стартира проект, който довежда до появата на първата комерсиална
машина ползваща кеш. Това е компютърът IBM System 360/85.
За направата на кеша се използва SRAM (статичен RAM), който е по-бърз
от DRAM и позволява достъп при работна честота близка до тази на микропроцесора.
Високата цена на статичната памет обаче ограничава количеството на кеша
и той обикновено заема само няколко стотин килобайта.
Действието на кеша е базирано на принципа на локалността. Съществуват
два вида локалност при работата на микропроцесора с работната памет:
-
временна локалност: Ако даден обект от паметта е бил използван веднъж,
вероятността той да бъде отново използван е голяма. Този принцип се отнася
до естествените циклични програмни структури (loops), които ползват едни
и същи инструкции и данни повече от веднъж.
-
пространствена локалност: Ако даден обект от паметта е използван веднъж,
то съседни на него обекти биха били използвани скоро след това. Тъй като
достъпът до инструкциите от паметта е последователен, програмите естествено
показват висока степен на локалност. Същото се отнася и до данните, които
често използват вектори(arrays) за тяхното подреждане.
Принципът на локалността позволява на кеша при един сравнително
ограничен размер да създава илюзията за бърза работна памет. Това става
по следния начин:
-
За спазване на временната локалност в кешовата памет се държи копие на
най-последните инструкции и данни. Ако микропроцесорът ги потърси отново,
те ще бъдат доставени от кеша, вместо от по-бавната работна памет.
-
За използване на пространствената локалност кешът се зарежда блоково от
работната памет, т.е. блок от няколко инструкции наведнъж. При Intel Pentium
един блок е с размер 32 байта. Блоковият характер позволява всяка следваща
инструкция да бъде доставена право от кеша, вместо да се зарежда инструкция
по инструкция от работната памет. Пространствената локалност се отнася
и до близки разклонения (branches), които могат да сочат към инструкция
от същия или съседен блок.
За описание на работата на кеша често се използват следните термини:
-
попадение (cache hit): означава, че търсеният обект е намерен в кеша
-
пропуск (cache miss): търсеният обект не е намерен в кеша и се налага той
да бъде зареден от работната памет вместо това
-
наказание (miss penalty): това е времето, което процесорът трябва да изчака
до зареждането на нужния обект от работната памет след пропуск
При съвременните компютри разликата в работната честота на процесора
и работната памет може да достигне фактор от 10 и повече. Плавният преход
тук се осигурява от многостепенен кеш, като всяко ниво работи на определна
междинна работна честота. При такава подредба информацията се движи само
между съседни нива, като горните осигуряват по-бърз дотъп, докато долните
кешови нива разполагат с по-голям капацитет.
Тези, които все още не са разбрали какво е това кеш, нека се запознаят
с хранителните навици на микропроцесора Pentium XIII и неговата кухня:
Pentium XIII е кулинар. Неговите специалитети са пълно отражение на
неговото ужасно сложно устройство, породено от тежкото наследствено бреме
още от времето на неговия прадядо 8086. Pentium XIII обича да готви по
няколко пъти на ден, което обуславя една непрестанна нужда от хранителни
продукти и напитки. Най-близкият супермаркет обаче се намира на километри
разстояние и всяко пазаруване отнема часове. Ами сега?
Тук няма място за тревога, защото Pentium XIII отдавна знае за магията
наречена кеш.
Затова той си е закупил хладилник и фризер (многостепенен кеш), които
заемат централно място в кухнята. Е, вярно е, че неговият братовчед Xeon
има по-голям хладилник, но какво да се прави като бюджетът е ограничен.
Да не говорим за бедния братовчед Celeron. Pentium XIII има и кола, с която
ходи да пазарува (ходене до работната памет) веднъж седмично. При всяко
пазаруване той пълни багажника догоре с продукти (блоково зареждане) така,
че да е запасен за по-дълго време.
И така днес Pentium XIII е поканил гости и ще готви пилешко филе. В
иделния случай филето бързо ще бъде доставено от хладилника (попадение).
Ако това не стане (пропуск), следва ровичкане из фризера. В него е доста
студеничко и ще мине час докато пилето се размрази (кешът от второ ниво
е по-бавен). Най-лошото е повторно ходене до супермаркета, но нека да не
дразним Pentium XIII, защото тези пазарувания наистина са го изнервили
напоследък (наказанието).
Един малък готварски експеримент
Разбира се, някои биха се запитали какво значение има кешът при писането
на програми. Ето един малък нарочен експеримент, при който трябва да се
извърши проста аритметична операция върху 10000 обекта. Те са разположени
по два различни начина в работната памет:
[1] Обектите са разпръснати в паметта и достъпът до тях изисква
големи "скокове" от един адрес на друг. "Скоковете" са в противоречие с
принципа на пространствената локалност и това би довело до голям брой кешови
пропуски.
[2] Обектите са разположени един до друг и достъпът до тях е последователен.
Това разположение е в съответствие с принципа на пространствената локалност
и кешът се използва ефективно.
Целта на експеримента е да определи процесорното време нужно за
изпълние на двата вида достъп.
Ето го и C кодът на двата варианта:
| [1] разпръснати обекти |
[2] последователни обекти |
struct vector{
double a;
double b;
double c;
double d;
double e;
};
struct vector v[10000];
void test()
{
int i;
for (i=0; i
< 10000; i++)
v[i].a +=
1.0;
} |
struct vector{
double a[10000];
double b[10000];
double c[10000];
double d[10000];
double e[10000];
};
struct vector v;
void test()
{
int i;
for (i=0; i
< 10000; i++)
v.a[i] +=
1.0;
} |
разпръснато подреждане на елементите от 'а' в паметта
|
последователно подреждане на елементите от 'а' в паметта
|
За извършването на експеримента е използвана C програма, която извиква
функцията test() десет хиляди пъти поред и след това изчислява средноаритметичното
процесорно време (CPU time) нужно за изпълнение на функцията при двата
варианта. Процесорното време отразява времето за изпълнение на програмните
инструкции и не включва изчакването за извършване на I/O операции, както
и времето прекарано в изпълнение на други процеси. То се измерва в своебразни
clock ticks, които лесно могат да бъдат превърнати в секунди.
| benchmark.c |
#include <stdio.h>
#include <time.h>
/* тестираният код е поставен тук */
int main (int
argc, char* argv[])
{
clock_t start, end;
double elapsed;
int i;
start = clock(); /* засича началото на цикъла */
for (i=0; i<10000;
i++)
test();
end = clock(); /* засича края на цикъла */
elapsed = ((double)(end
- start)) / CLOCKS_PER_SEC / 10000;
printf("%s: elapsed CPU time
is %f sec.\n", argv[0], elapsed);
return(0);
}
|
Програмата е компилирана в двата варианта с gcc с опция -О2, която извършва
оптимизация до второ ниво (виж man gcc).
За експеримента са използвани четири различни компютъра работещи под
Unix. Те ползват следните микропроцесори:
[1] Dual Intel Pentium III, 800MHz, 32-битов, 256KB L2 кеш
[2] Intel Pentium III, 450MHz, 32-битов, 512KB L2 кеш
[3] Sun UltraSPARC, 143MHz, 64-битов, 256KB L2 кеш
[4] IDT C6, 200MHz, 32-битов, 64КБ L2 кеш
[5] Hitachi SH 486SLC, 25MHz, 32-битов, без кеш
Разултатите са събрани в следната графика, показваща средното процесорно
време в милисекунди нужно за изпълнението на един цикъл от 10000 достъпа
при двата варианта:
|
Време за изпълнение според положението на обектите в работната
памет, ms
|
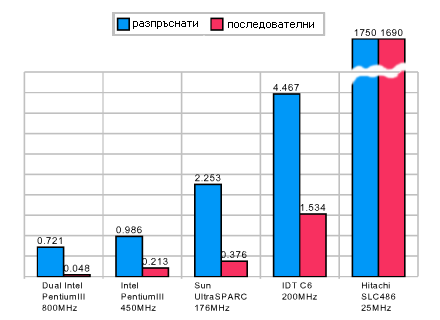
|
От графиката ясно се вижда, че при микропроцесорите ползващи кешова
памет се наблюдава зависимост между бързината на изпълнение на кода и положението
на обектите в паметта. При 486 процесора, който не ползва кеш, това дали
обектите са един до друг или разпръснати из работната памет изглежда не
играе съществена роля, въпреки доста бавното изпъление на програмата. При
неговите събратя обаче неефективното използване на кеша е довело до значителни
изоставания в бързината. Факторите на забавяне са представени за по-прегледно
в следната графика.
|
Фактор на забавяне при разпръснати обекти
|
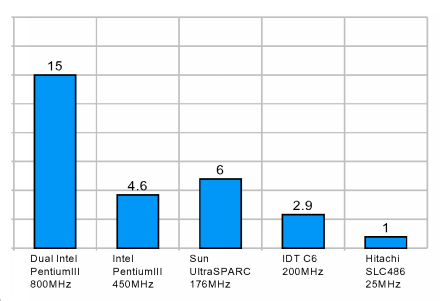
|
При 486 факторът е 1, т.е. няма забавяне. При останалите процесори обаче
то е приблизително 3 до 15 пъти! Pentium III 800MHz се представя най-зле,
защото при него разликата между работните честоти на микропроцесора и паметта
е най-голяма - приблизително около 8 пъти.
Нуждата от кеш ориентирано програмиране
Горният експеримент все пак си остава един нарочен опит да се представят
най-лошите ефекти от програмиране, което не ползва ефективно кешовата памет.
Правени са многобройни експерименти и с практически приложения, където
е било отчитано отношението на кешовите пропуски към кешовите попадения
(miss rate). На DEC Station познатият ни gcc е показал пропускно отношение
от 5.4%, а програмата spice отношение от 1.2%. Фактическото забавяне пък
се определя от пропускното отношение и латентността на работната памет
спрямо микропроцесора.
Нуждата от кеш ориентирано програмиране е най-голяма там, където наказанието
от кешов пропуск е най-тежко. Например при обработка на големи масиви от
данни (база данни), сложни изчислителни процедури (3D графики) или критични
процеси работещи в реално време (разпознаване на образи). Други фактори
са ползата от една кешова оптимизация, дали тя е въобще възможна, както
и непълноценното използване на инвестицията в по-бърз микропроцесор.
Затова и самата нужда от кеш ориентирано програмиране си остава повече
или по-малко специфична. Не бива да забравяме и нервите на нашия Pentium
800, който по време на горния експеримент прекара 93% от времето си в чакане
някой да му подхвърли поредния double.
Кратка рецепта за кеш ориентирано програмиране
Принципът на локалността по един сравнително добър начин описва обикновената
мисловна дейност на човека и следователно и една голяма част от програмите
писани от него. Различните програмни езици също така до различна степен
следват принципа на локалността. Процедурни езици като Assembler и C предлагат
по-големи възможности за кеш ориентирано програмиране отколкото абстрактните
обектно-ориентирани езици като C++ и Java. Проблемът се състои в несъвършените
компилатори, които не могат да вникнат в контекста на програмния код, където
са вложени голяма част от идеите на програмиста. Затова ако програмистът
не е запознат със смисъла на програмния език и слабостите на неговия компилатор,
при превръщането на програмата в машинен код безвъзвратно се губи част
от нейната локалност. Това пък от своя страна води до една по-бавна програма.
Ето кратка рецепта с основните принципи за кеш ефективно програмиране,
разбира се подкрепена с C примери:
-
За експлоатиране на временната локалност, концентрирайте операциите върху
даден обект във възможно най-малък блок от програмния код. Ако трябва да
извършите някакви изчисления върху даден вектор, особено ако той е голям,
направете ги всичките на същото място.
При следната рутина се умножават елементите от вектора a[k] със
съответните елементи от b[k], след което към а[k] се прибавят елементите
от вектора c[k]. Това може да бъде направено с два цикъла по следния начин:
for (k = 0; k < size; k++)
a[k] = a[k] * b[k];
for (k = 0; k < size; k++)
a[k] = a[k] + c[k]; |
По-изгодно е да извършим всички операции за даден елемент наведнъж и
след това да преминем към следващия. По този начин даден елемент от a[k]
се зарежда в кеша само веднъж, което спестява допълнителното зареждане
от горната версия:
for (k = 0; k < size; k++)
a[k] = a[k] * b[k] + c[k]; |
Оптимизираната рутина дава ускорение от 9% на една Sun работна станция.
-
За експлоатиране на пространствената локалност, достъпът до обекти от паметта
трябва да бъде извършван с възможно най-малка стъпка. В идеалния случай
ще преминаваме от един адрес на съседен.
Първият пример се отнася до достъпа до елементите от една двуизмерна
матрица. Компилаторът разполага елементите от матрицата в паметта ред по
ред. При следната рутина за събиране на две матрици този факт е пренебрегнат
и това води до скокове в паметта през цял ред:
for (col = 0; col < size; col++)
for (row = 0;
row < size; row++)
x[row][col] = y[row][col]
+ z[row][col]; |
Затова променяме реда на циклите от col, row на row, col:
for (row = 0; row < size; row++)
for (col = 0;
col < size; col++)
x[row][col] = y[row][col]
+ z[row][col]; |
В зависимост от големината на матрицата оптимизацията може да ускори
изпълнението до няколко пъти.
Вторият пример се касае до пространствената локалност на програмните
инструкции. Тя може лесно да бъде нарушена при извикването на отделни малки
функции, но все пак не бива да забравяме и факта, че функциите правят кода
по-прегледен и лесен за поддръжка. За щастие много C компилатори поддържат
т.нар. вграждане или "function inlining". То се активира с ключовата дума
"inline", която казва на компилатора да вгради кодът на функцията във всяка
рутина, която я извиква.
Ето една малка функция, която си струва да вградим:
inline double radius_of( Node& node
)
{
return sqrt( node.x*node.x + node.y*node.y
+ node.z*node.z );
} |
За повече информация относно вграждането е добре да се прочете документацията
към компилатора, защото "inline" не е част от ANSI C. Понякога е нужно
допълнително активиране на вграждането със специална командна опция при
компилирането.
-
Разбира се има и случаи, когато временната и пространствената локалност
трябва да се приложат комбинирано. При комбинираното им ползване обаче
могат да възникнат и противоречия. С по-внимателен анализ и малко експериментиране
може да стигнем лесно до компромис.
Ето една често срещана рутина, където двата принципа се разглеждат
едновременно. Става въпрос за умножението на две матрици. Тук трябва да
следим както последователното преминаване през елементите на матрицата,
така и тяхното повторно използване.
for (i = 0; i < size; i++)
for (j = 0;
j < size; j++)
for (k = 0;
k < size; k++)
x[i][j] = x[i][j] + y[i][k] * z[k][j]; |
На пръв поглед подредбата изглежда логична, но ако променим реда на
циклите на k, j, i, на една работна станция Silicon Graphics с 1MB L2 кеш
и size = 500 бихме забелязали ускорение от близо два пъти.
Надявам се тази рецепта да послужи успешно при укротяването на вашия
bogomips звяр.
Изтънчване на рецептите
За търсачите на по-изтънчени рецепти предлагам следните усложнени решения:
-
Много от модерните микропроцесорни архитектури предлагат специфични инструкции
за манипулиране на кеша. Така например в PowerPC са включени пет такива
инструкции: data cache block flush, data cache block store, data cache
block touch for store и data cache block set to zero. Тези инструкции обаче
са риск за преносимостта, дори между PowerPC процесори ползващи различни
по големина кешови блокове.
-
Съществуват експериментални приложения, които комбинират компилатора и
т.нар. профилатор или "profiler". Процедира се по следния начин: При компилирането
на програмата в нея се вкарва допълнителен код след което програмата се
пуска. Допълнителният код следи по какъв начин програмата използва кешовата
памет. На базата на резултатите се прави план за оптимизация, след което
програмата се компилира за втори и последен път без допълнителния код.
-
Интересно решение е и кешовият симулатор CProf, създаден в Duke University,
USA. Той симулира работата на кешовата памет на UltraSPARC процесор и може
да се използва за разпознаване на критични участъци в дадена C програма.
За съжаление симулаторът не се предлага като свободен софтуер и лицензът
струва $1000.
За написването на настоящия материал са използвани различни програмни
екперименти както и следните публикации (печатни, но сигурно има и копия
из мрежата):
[1] Mike Phillip, "Zen and the Art of Cache Maintenance", 1997
[2] Alvin Lebeck, "Cache Conscious Programming in Undergradute Computer
Science", 1999
[3] Brad Calder et all, "Cache-conscious Data Placement", 1998
Успех в готвенето!
Владимир Джувинов
За коментари и въпроси : [email protected]
(моля, не ме питайте как PXIII е сготвил пилешкото филе)
20.10.2000