В този материал се описва какво представлява един процес, и как Linux ядрото създава, управлява и унищожава процесите
в системата. Процесите изпълняват задачи вътре в операционната система. Програмата представлява множество от машинни инструкции и данни,
които се съхраняват в изпълним файл на диска и като такова то е една пасивна единица.
Можете да си представите процеса като компютърна програма в действие. Той е една динамична единица, постоянно променяща
се при изпълнението на машинните инструкции от процесора. Както инструкциите и данните на програмата, процесът включва програмен брояч и всички
регистри на процесора, а също стекове за процеси, съдържащи временни данни - например функционални параметри, адреси на връщане и запазени
променливи. Програмата или процеса, който се изпълнява в момента, иззема всички ресурси на микропроцесора.
Linux обаче е операционна система, която управлява множество процеси. Те са отделни задачи, всяка със собствени права и отговорности. Ако един
процес "забие", то това няма да причини "забиването" и на други процеси. Всеки отделен процес работи в свое собствено виртуално адресно пространство
и не може да общува с други процеси освен чрез подсигурени, управлявани от ядрото механизми.
През "живота" си един процес използва множество системни ресурси. Използва CPU-то на системата, за да изпълнява
инструкциите си, а също и системната физическа памет, за да помещава в нея себе си и своите данни. Той отваря и използва файлове във файловите
системи и може директно или индиректно да използва физическите устройства в системата. Linux трябва сам да следи процеса и системните ресурси,
които има, за да може "честно" да управлява и другите процеси в системата. Не би било справедливо за останалите процеси, ако един от тях монополизира
по-голямата част от системната физическа памет или процесор(ите).
Най-ценният ресурс в системата е централният процесор, и обикновено той е един. Linux е операционна система, която управлява
множество процеси, и неговата цел е да има по един процес, работещ на всеки процесор в системата по всяко време, за да се увеличи полезността на
процесора. Ако има повече процеси, отколкото процесори (както обикновено става), останалите процеси трябва да изчакат, преди процесора да се
освободи, за да могат да се стартират и те. Мултипроцесинга е просто нещо; всеки процес се изпълнява, докато трябва да изчака, обикновено за някой
системен ресурс; когато той получи необходимия ресурс, може отново да се стартира. В една еднопроцесна система, като например ДОС, CPU-то
просто ще си седи тихо и така ще бъде пропиляно времето за изчакване. В друга, многопроцесна система множество процеси се пазят в паметта
по едно и също време.
Linux поддържа няколко различни изпълними файлови формати. ELF е един от тях, Java е друг, и те трябва да бъдат управлявани
прозрачно, както и процесите трябва да използват поделените системни библиотеки.
1. Linux процеси
И така, за да може Linux да управлява процесите в системата, всеки процес се представя от структура от данни task_struct (task и process, или задача
и процес, са термини, които в Linux се използват взаимозаменяемо). Векторът на задачите е масив от указатели към всяка task_struct структура от
данни в системата.
Това означава, че максималният брой процеси в системата е ограничен от големината на таск вектора (вектора на задачите)
- по подразбиране той включва 512 указателя. Когато се създават процеси, от системната памет се отпуска нов task_struct и се допълва към
вектора на задачите. За да бъде по-лесен за откриване, текущият указател сочи към текущият, работещ процес.
Освен обикновените процеси, Linux поддържа и т.нар. "реално времеви" (real time) процеси. Те трябва да реагират много
бързо на външни събития (оттук идва и определението реално времеви) и са третирани по различен начин от нормалните потребителски процеси от
Scheduler -а. Въпреки че структурата от данни task_struct е доста обширна и сложна, полетата й могат да бъдат разгледани като няколко функционални
области:
Състояние
Когато един процес се стартира, той променя полето Състояние съгласно обстоятелствата. Процесите в Linux имат
следните състояния:
Работещи
Процесът или работи (т.е. е текущият процес в системата) или е готов да бъде стартиран (т.е. чака да му бъде присвоен един
от процесорите на системата)
Чакащи
Процесът чака някакво събитие или ресурс. Linux различава два типа процеси – прекъсваеми и непрекъсваеми. Прекъсваемите
чакащи процеси могат да бъдат прекъсвани от сигнали, докато непрекъсваемите се осланят директно на хардуерните състояния, и не могат да бъдат
прекъсвани при никакви обстоятелства.
Спрени
Процесът е бил спрян, обикновено при получаване на сигнал. Процес, който се дебъгва, може да бъде в спряно състояние.
Зомби
Това е спрян процес, който все още, по някаква причина, има task_struct структури от данни в таск вектора. Това е точно както
си звучи - мъртъв процес.
Информация за разписанието
Scheduler -ът има нужда от тази информация, за да може справедливо да решава кой процес в системата най-много
"заслужава" да бъде стартиран.
Идентификатори
Всеки процес в системата има идентификатор на процеса. Този индикатор не е индекс в таск вектора, а просто едно число.
Освен това всеки процес има потребителски и групови идентификатори, които се използват за контролиране на достъпа на този процес до файлове и
устройства в системата.
Комуникация между процесите
Linux поддържа класическите UnixTM IPC механизми за сигнали, пайпове и семафори, както и
System V IPC механизмите на поделената памет, семафори и опашки от съобщения.
Връзки
В една Linux система никой процес не е независим от който и да е друг процес. Всеки процес в системата, освен стартиращия,
си има свой родителски процес. Новите процеси не се създават, те се копират, или по-скоро клонират от предишни процеси. Всеки task_struct,
представящ един процес, пази указателите към своя родителски процес и към своите сиблинги (т.е. към процесите, които имат един и същ процес-родител),
както и към своите собствени процеси-потомци. Можете да видите семейните зависимости между работещите процеси в една Linux система чрез
командата pstree:
init(1)-+-crond(98)
|-emacs(387)
|-gpm(146)
|-inetd(110)
|-kerneld(18)
|-kflushd(2)
|-klogd(87)
|-kswapd(3)
|-login(160)---bash(192)---emacs(225)
|-lpd(121)
|-mingetty(161)
|-mingetty(162)
|-mingetty(163)
|-mingetty(164)
|-login(403)---bash(404)---pstree(594)
|-sendmail(134)
|-syslogd(78)
`-update(166)
Допълнително всички процеси в системата се държат в двойно свързан списък, чийто корен е task_struct структурата от данни
на init процесите. Този списък позволява на кернела да наглежда всички процеси в системата. Това е необходимо, за да се предостави поддръжка
за команди като ps и kill.
Времена и таймери
Ядрото следи за времето на създаване на процесите, както и за процесорното време, което те консумират докато съществуват.
На всеки такт на часовника кернела обновява количеството време в тактове, което текущия процес е прекарал в системата и в потребителски режим.
Linux освен това поддържа специфични за всеки процес таймери на интервалите, а процесите могат да използват системни обръщения за настройката
на таймери, изпращащи им сигнали, когато времето на таймера изтече. Тези таймери могат да бъдат единични или периодични.
Файлова система
Процесите могат да отварят и затварят файлове когато си пожелаят, а във task_struct на всеки процес се съдържат указатели
към дескрипторите за всеки отворен файл, както и указатели към два VFS i-възела. Всеки VFS i-възел описва уникално един файл или директория
във файловата система и предоставя единен интерфейс към намиращите се на по-ниско ниво файлови системи. Първият възел
сочи към root-а на процеса (неговата home-директория), а вторият към текущата работна директория. Тези два i-възела имат свои броячни полета,
обозначаващи един или повече процеси, които имат отношение към тях. Това е така, защото не можете да изтриете директория, която някой процес има за
текуща.
Виртуална памет
Повечето процеси имат някаква виртуална памет (нишките на кернела и демоните нямат) и кернела на Linux трябва да
следи как се разпределя виртуалната памет във физическата памет на системата.
Специфичен контекст на процесора
Можем да си представим един процес като сума от текущото състояние на системата. Когато един процес работи, той използва
регистрите и стековете на процесора. Това е контекстът на процеса, и когато един процес е преустановен временно, целият този специфичен контекст
на централния процесор трябва да бъде запазен в task_struct за този процес. След това, когато процесът е рестартиран отново от разпределителя,
контекстът му се възстановява от тук.
2. Идентификатори
Linux , като всички Unix системи използва потребителски и групови идентификатори за проверка на правата за достъп до
файловете и дяловете в системата. Всички файлове в една Linux система имат притежатели и права (permission , англ. - позволение), които описват
какъв достъп имат потребителите на системата до този файл или директория. Основните позволения са за четене, запис и изпълнение и се отнасят до три
групи потребители: собственикът на файла; процеси, принадлежащи на определена група и всички процеси в системата. Всеки клас потребител може да
има различен достъп, например един файл може да има определени права за достъп, позволяващи на собственика му да го чете и да записва в него,
групата само да го чете, а останалите потребители да нямат никакви права върху него.
Групите са "линукс"-кия начин да се присвояват привилегии върху файлове и директории на група потребители вместо на един
потребител или на всички процеси в системата. Вие можете например да създадете група за всички потребители в един софтуерен проект, и да кажете,
че само те могат да четат от и да пишат в сорс кода на проекта. Един процес може да принадлежи на няколко групи (максимумът по подразбиране
е 32), а те се пазят във вектора на групата в task_struct за всеки процес. Докато един файл има права за достъп до една от групите, към която
принадлежи процеса, тогава този процес ще има съответните групови права за достъп до този файл.
Това са четирите двойки процеси и идентификатори на групи, които се пазят в task_struct на всеки процес:
uid, gid (user id, group id)
Това са потребителският и груповият идентификатори на потребителя, от чието име е стартиран процеса,
Ефективен uid и gid
Има някои програми, които променят uid -а и gid -а от тези на изпълняващия се процес в свои собствени
(съдържат се като атрибути на всеки VFS i-възел, описващ изпълним файл). Тези програми са известни като setuid програми, и са полезни, защото
това е един начин за забраняване на достъпа до някои услуги, по-специално тези, които се стартират от името на някой друг, например един мрежов
демон.
Uid и gid на файловата система
Те обикновено са същите като ефективните uid и gid , и се използват, когато се проверява за правата за достъп до
файловата система. Необходими са за файлови системи, монтирани като мрежови, където NFS сървъра в потребителски режим има нужда
от достъп до файловете все едно, че е специален процес. В този случай се променят само uid-а и gid-а на файловата система (а не ефективните
uid и gid ). По този начин се избягват ситуации, в които злонамерени потребители биха могли да изпратят.
Запазени uid и gid
Те произлизат от POSIX стандарта и се използват от програми, които променят uid-а и gid-а на процесите чрез системни
обръщения. Използват се, за да запазят истинските uid и gid през времето, в което оригиналните uid и gid са променени.
3. Разписание
Всички процеси се стартират частично в потребителски режим и частично в системен. Начинът, по който тези режими се поддържат
от хардуера на ниско ниво, се различава, но в най-общи линии представлява един осигурен механизъм за преминаване от потребителски в системен режим
и обратно. Потребителският режим има много по-малко привилегии, отколкото системния. Всеки път, когато един процес направи системно обръщение,
той се прехвърля от потребителски в системен режим и продължава да се изпълнява. В този момент кернелът се изпълнява от името на този процес.
В Linux останалите процеси не "превъзхождат" текущия, работещ процес; те не могат да го спрат, за да тръгнат самите те. Всеки процес решава
да отстъпи CPU-то, на което работи, когато трябва да изчака някакво системно събитие.
Процесите винаги правят системни обръщения и затова често може да им се наложи да изчакват. Дори и в този случай, ако
един процес се изпълнява, докато чака, той все пак може да използва някаква непропорционална част от времето на CPU-то, и затова Linux
използва предварително разписание. В тази схема на всеки процес се разрешава да работи за малко, например 200 милисекунди, и когато неговото
време изтече, се избира друг процес, който да се стартира, а оригиналният изчаква за малко, докато може отново да бъде стартиран. Това малко
количество време е известно като "времеви отрязък".
Именно програмата, определяща разписанието трябва да избере кой от всички процеси подлежащи на стартиране в системата
"заслужава" най-много това. Подлежащ на стартиране процес е този, който чака за свободно CPU , на което да се стартира. Linux използва разумно
опростен алгоритъм, базиран на приоритети, за да избере между текущите процеси в системата. Когато той избере да стартира някой нов процес
запазва състоянието на настоящия, а специфичните регистри на процесора и други контекстно зависими данни се запазват в структурата от данни
на процеса task_struct . След това той възстановява състоянието на новия процес (това отново е специфично за всеки процесор), който ще бъде стартиран
и му дава контрола върху системата. За да може програмата, определяща разписанието, справедливо да разпредели CPU времето между стартираните процеси.
политика (спрямо този процес)
Това е правило за определяне на разписанието, която ще бъде прилагана спрямо този процес. Има два вида процеси в Linux
- нормални и реалновремеви . Реалновремевите процеси имат по-висок приоритет, отколкото всички останали. Ако има чакащ реалновремеви
процес, той ще бъде стартиран първи. Реалновремевите процеси се третират по два начина - "кръгови" и "първи влиза - първи излиза".
При "кръговото" разписание всеки реалновремеви процес, който подлежи на стартиране се пуска поред, а при "първи влиза - първи излиза" всеки
реалновремеви процес, който подлежи на стартиране се пуска по реда на опашката за изчакване, и този ред никога не се променя.
приоритет
Това е приоритетът, който ще бъде даден на този процес от програмата, определяща разписанието. Това е също и количеството
време (в тактове), през което този процес ще работи, докато му е позволено. Приоритетът на един процес може да бъде променен чрез системни
обръщения и чрез командата renice.
реалновремеви приоритет
Linux поддържа процеси в реално време и те имат по-висок приоритет в разписанието, отколкото всички други в системата,
които не са в реално време. Това поле позволява на програмата, определяща разписанието да даде на всеки реалновремеви процес съответния приоритет.
Приоритетът на реалновремевите процеси може да бъде променен с използването на системни обръщения.
брояч
Това е количеството време (в тактове), през което на този процес му е позволено да работи. То е установено по приоритет,
когато процесът е стартиран за първи път и се намалява с единица при всеки такт на системния часовник.
Програмата за определяне на разписанието се стартира от няколко места в ядрото. Стартира се след поставянето на текущия
процес в опашката за изчакване, а също може да бъде стартирана на края на системно обръщение, точно преди процесът да бъде върнат от системен
в процесен режим. Една от причините, поради които може да има нужда да се стартира е защото системния таймер току-що е установил брояча на
текущите процеси на нула.
Всеки път, когато тази програма се стартира, тя прави следното:
работа на ядрото
Scheduler -ът стартира долната половина манипулатори и обработва опашката със задачи.
текущ процес
Текущият процес трябва да бъде обработен преди някой друг процес да бъде избран за стартиране.
Ако политиката за стартиране е кръгова, той се поставя обратно на опашката за изчакване. Ако задачата е ПРЕКЪСВАЕМА
и е получила сигнал от последния път, когато е била определена за стартиране насам, то нейното състояние става РАБОТЕЩА.
Ако текущият процес е прехвърлил времето си, то състоянието му става РАБОТЕЩ.
Ако текущият процес е РАБОТЕЩ, то той остава в това си състояние.
Процесите, които не са били нито ПРЕКЪСВАЕМИ, нито РАБОТЕЩИ се отстраняват от опашката за изчакване.
Това означава, че те няма да бъдат избрани за стартиране, когато Scheduler-ът търси кой процес "заслужава" най-много да бъде стартиран.
Избиране на процеси
Scheduler -ът преглежда процесите в опашката за изчакване, търсейки кой процес "заслужава" най-много да бъде стартиран.
Ако има някакви реалновремеви процеси (такива с реалновремева политика на разписанието), то те ще "тежат" повече от обикновените процеси.
Теглото на един нормален процес е неговият брояч, но на един реалновремеви процес е броячът плюс 1000. Това означава, че ако има някакви реалновремеви
процеси в системата, които чакат стартиране, то те винаги ще бъдат стартирани преди нормалните процеси. Текущият процес, който е консумирал малко
от своето време (т.е. броячът му е бил намален с единица) е в несгода, ако има други процеси с равен приоритет в системата; така и би трябвало да бъде.
Ако няколко процеса имат еднакъв приоритет, се избира този, който е най-близо до началото на опашката за изчакване. Текущият процес бива поставен
на края на опашката. В балансирана система с множество процеси с еднакъв приоритет всички се стартират подред. Това е именно кръговата политика.
Swap процеси
Ако най-заслужаващият да бъде стартиран процес не е текущият, то текущият трябва да бъде преустановен, а новият да бъде
стартиран. Когато един процес работи, той използва регистрите и физическата памет на CPU -то и на системата. Всеки път, когато извика някоя функция,
той подава аргументите си в регистрите и може да стекира запазени стойности, като например адрес на връщане в извиканата функция. И така, когато
Scheduler-ът работи, той работи в контекста на текущия процес. Може да е в привилигерован режим, в кернел-режим, но все пак той е текущият
работещ процес. Когато на този процес му дойде времето да бъде преустановен, цялото му машинно състояние, включително програмният брояч и
всички процесорни регистри, трябва да бъде запазено в структурата от данни на процеса task_struct. Тогава се зареждат всички машинни състояния за новия
процес. Това е системно зависима операция.
Тази размяна на контекста на процесите става в края на Scheduler-а. Запазеният контекст на предишния процес следователно
е "моментална снимка" на хардуерния контекст на системата, какъвто е бил той по времето на края на Scheduler-а. Също така когато бъде зареден
контекста на нов процес, той също ще бъде "моментална снимка" на това как са стояли нещата на края на Scheduler-а, включително програмния брояч
на този процес и съдържанието на регистрите.
Ако предишният или текущият процеси използват виртуалната памет, то пейджинг таблицата на системата може да има нужда
от обновяване. Това отново е специфично за всяка архитектура. Процесори като Alpha AXP, които използват Translation Look-aside таблици или
кешират пейджинг таблицата, трябва да изчистят кешираните данни, които принадлежат на предишния процес.
3.1. Разписание при многопроцесорни системи
Системите с много процесори (CPU-та) са рядко срещани в света на Linux, но работата по превръщането на Linux в SMP
(Симетрична МногоПроцесорна) система вече е доста напреднала. (Все повече многопроцесорни системи се управляват от Linux в последните
няколко години - бел. Linux center) Една такава система е способна дори да балансира натоварването на отделните
процесори в системата. Това балансиране на натоварването не се вижда никъде другаде така добре, както в Scheduler-а.
В една многопроцесорна система, слава Богу, всеки от процесорите е зает с изпълняване на процеси. Всеки ще стартира
Scheduler-а, когато текущият му процес изхаби своя времеви отрязък или когато трябва да чака за системен ресурс. Първото нещо, което трябва да
се отбележи в една SMP система е, че там има не само един чакащ (idle) процес. В еднопроцесорната система чакащият процес е първата задача
в task вектора, а в една SMP система има по един чакащ процес на всяко CPU, а можете да имате повече от един свободен процесор, следователно
SMP системите водят баланс за текущите и чакащите процеси за всяко CPU.
В една многопроцесорна система всеки task_struct на процес съдържа номера на процесора, на който той се изпълнява,
а също и номера на процесора, на който е бил изпълняван последно. Няма причина един процес да не тръгне на различен процесор всеки път, когато
бъде избран да се стартира, но Linux може да ограничи този процес до един или повече процесори в системата чрез processor_mask. Ако е установен
бит N, то тогава този процес може да бъде стартиран на процесор N. Когато Scheduler-ът избира нов процес, който да бъде стартиран, той няма да
вземе предвид такъв процес, който няма установен съответния бит N в своя processor_mask.
4. Файлове
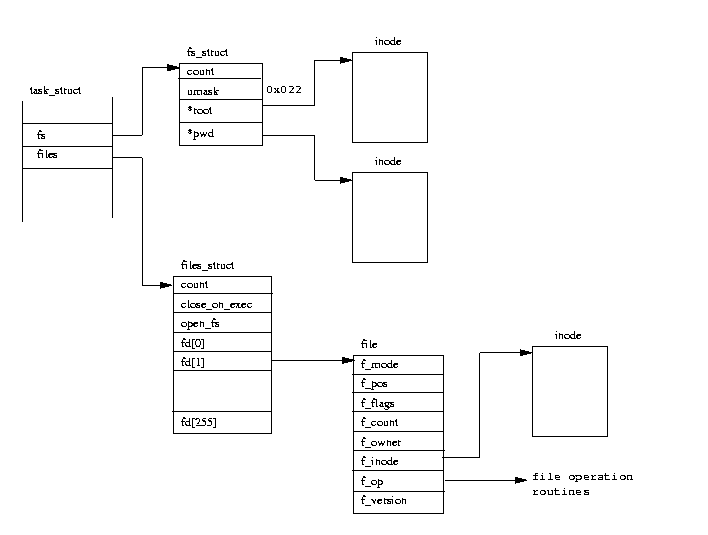
Фигура 1 показва, че има два вида структури от данни, които описват специфична информация, свързана с файловата система
за всеки процес в системата. Първата - Fs_struct съдържа указатели към VFS i-възлите на този процес и към неговата umask. Umask е режимът
по подразбиране в който се създават новите файлове, и той може да бъде променян чрез системни обръщения.
Втората структура от данни - files_struct , съдържа информация за всички файлове, които този процес използва в момента.
Програмите четат от стандартен вход и пишат в стандартен изход. Всички съобщения за грешки би трябвало да се изпращат към стандартната грешка.
Това може да са файлове, терминален вход/изход, или истинско устройство, но доколкото програмата се интересува от това - всичко е файлове. Всеки
файл има свой собствен дескриптор и files_struct съдържа указатели към максимум 256 структури с файлови данни, като всяка описва един файл,
използван от този процес. Полето f_mode описва в какъв режим е бил създаден файла: само четене, четене и писане, или само писане. f_pos сочи позицията
във файла където се очаква да се случи следващото писане или четене. f_inode сочи VFS i-възела описващ файла.
Всеки път, когато бъде отворен файл, се използва един от свободните файлови указатели в files_struct, за да сочи към новата
файлова структура. Когато бъдат стартирани, процесите в Linux очакват да бъдат отворени три файлови дескриптора. Те са известни като
standard input, standard output и standard error (стандартен вход, стандартен изход и стандартна грешка), и обикновено се наследяват от създаващите ги родителски процеси. Всеки достъп до файл става
посредством стандартни системни обръщения, които подават или връщат файлови дескриптори. Тези дескриптори сочат към fd вектора на
процеса, така че standard input, standard output и standard error имат файлови дескриптори 0,1 и 2. Всеки достъп до файла използва структурата от
файлови данни на оперативните функции на файла заедно с VFS i-възела.
5. Виртуална памет
Виртуалната памет на един процес съдържа изпълним код и данни от много източници. Първо, това е програмното
изображение, което е заредено; например една команда като ls . Тази команда, като всички изпълними изображения, се състои както от изпълним
код, така и от данни. Файлът с изображението съдържа цялата необходима информация, за да се зареди изпълнимият код и асоциираните програмни
данни във виртуалната памет на процеса. Второ, процесите могат да си определят (виртуална) памет, която да използват по време на обработката,
която може да се използва да кажем за помещаване съдържанието на файловете, които този процес чете. Тази новоразпределена, виртуална, памет
трябва да бъде свързана със съществуващата вече виртуална памет на процеса, така че да може да бъде използвана. Трето, процесите в Linux
използват библиотеки с обобщен код. Няма значение дали всеки процес има свое копие на библиотеките, зашото Linux допуска споделянето им между процеси
изпълнявани по едно и също време.
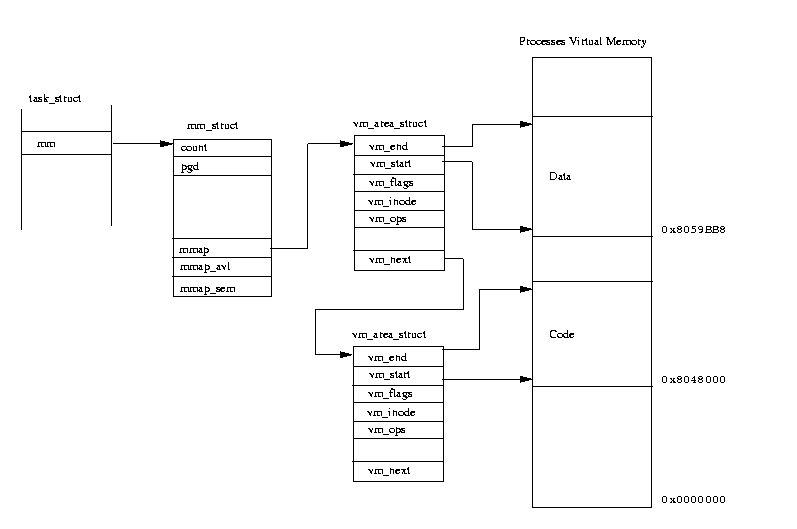
Фигура 2: Виртуалната памет на един процес
Linux кернела трябва да може да управлява всички области от виртуалната памет. Съдържанието на виртуалната памет на
всеки процес се описва от структурата от данни mm_struct , която е посочена от своята task_struct. Структурата от данни mm_struct на процеса
също съдържа информация за зареденото изпълнимо изображение и указател към page таблиците на процеса. Тя съдържа указатели към списък от
структури от данни vm_area_struct , като всяка от тях представлява една област от виртуалната памет в този процес. Този свързан списък е в увеличаващ
се порядък на виртуалната памет. Фигура 4.2 показва план на виртуалната памет на един обикновен процес, заедно с структурата от данни на ядрото, което я
управлява.
Linux кернела постоянно работи с множеството от vm_area_struct структури от данни на всеки процес, когато създава
нови области виртуална памет за процеса и когато поправя указанията към виртуалната памет, която не е в системната физическа памет.
Поради това времето, необходимо за намирането на правилната vm_area_struct , е критично за производителността на системата. За да се ускори достъпа,
Linux подрежда vm_area_struct структурите от данни в така нареченото дърво AVL (Adelson-Velskii and Landis). Това дърво е така устроено, че всяка
vm_area_struct (или възел) има ляв и десен указател към съседните vm_area_struct структури. Левият сочи възел с по-малък виртуален адрес, а десният с по-висок.
За да намери правилният възел Linux- a тръгва от корена и следва левите и десни указатели на всеки възел докато намери правилната vm_area_struct.
Разбира се, няма нищо безплатно - вмъкването на нова структура в дървото отнема процесорно време.
Когато един процес отдели виртуална памет, всъщност не може да се каже че Linux резервира физическа памет него.
Вместо това, той описва виртуалната памет, като създава нова vm_area_struct . Тя се свързва със списъка на виртуалната памет на този процес.
Когато процесът се опита да пише във виртуален адрес в рамките на региона на новата виртуална памет, тогава системата ще изведе грешка в
страницата. Процесорът ще се опита да декодира виртуалният адрес, но тъй като не съществуват никакви Page Table Entries, за която и да е от
тази памет, той ще се откаже и ще обяви page fault exception, оставяйки Linux кернела да оправи нещата. Ядрото проверява дали виртуалните адреси
се отнасят към текущото виртуално адресно пространство на процеса и ако е така запазва страница от физическата памет за този процес. Може и да е необходимо
код или данни да бъдат прехвърлени във физическата памет от файл или от swap диска. Процеса може да бъде рестартиран от инструкцията, която е предизвикала
page fault-а и тъй като паметта вече физически съществува тя ще бъде изпълнена.
6. Създаване на процес
Когато системата бъде стартирана, тя тръгва в т.нар. “ kernel mode, и в този смисъл има само един, първоначален процес.
Както и всички други процеси, първоначалният процес има машинно състояние, което се представя от стекове, регистри и т.н. Те ще бъдат запазени
task_struct структурата от данни на този процес, когато в системата бъдат създадени и стартирани други процеси. В края на системната инициализация
първоначалният процес стартира една нишка в кернела (наречена init ), след което остава в празен цикъл, не вършейки нищо. Когато няма нищо друго
за правене, scheduler -ът ще стартира този “бездеен” процес. Task_struct на такъв процес е единствената, която не се заделя динамично и често
погрешно бива наричана init task.
Init нишката на кернела има идентификатор на процеса 1, тъй като е първият истински процес в системата. Той прави някои
първоначални настройки в нея (като например отварянето на системната конзола и монтирането на root файловата система), а след това изпълнява
системната инициализираща програма. Тя е една от /etc/init , /bin/init или /sbin/init , в зависимост от вашата система. Инициализиращата програма
използва /etc/inittab като скрипт файл, за да създава нови процеси в системата. Тези нови процеси могат сами да продължат да създават нови процеси
Например getty процеса може да създава login процес, когато потребител се включва логически към системата.
Нови процеси се създават чрез клонирането на стари, или по-точно чрез клонирането на текущия процес. Нова задача се
създава чрез системно обръщение (fork или clone) , и клонирането става в кернела. В края на системното обръщение вече има нов процес, чакащ
да бъде стартиран, веднъж щом бъде избран от scheduler -а. Създадена е нова структура от данни task_struct във физическата системна памет,
с една или повече физически страници за стековете на клонираните процеси (потребителски и на кернела). Може да бъде създаден нов идентификатор
на процеса, и той ще бъде уникален в множеството от идентификатори на процеси на системата. Но е напълно разумно клонираният процес да запази
идентификатори на родителския си процес. Новата task_struct се добавя във вектора на задачите и съдържанието на родителската task_struct се копира
в клонираната task_struct.
Когато се клонират процеси, Linux позволява двата процеса да ползват поделени ресурси, вместо да имат отделни такива.
Това се отнася до файловете на процеса, манипулаторите на сигнали и виртуалната памет. Когато тези ресурси ще се поделят, съответните им броячи
се увеличават с единица, за да не би Linux да преразпредели тези ресурси, докато двата процеса не свършат работата си с тях. И така например, ако
клонирания процеси използва поделена виртуална памет, неговата task_struct ще съдържа указател към mm_struct на оригиналния процес, а тази
mm_struct ще има брояч, увеличен с единица, който показва броя процеси, които я поделят.
Клонирането на виртуалната памет на един процес е доста хитро направено. Трябва да бъде генерирано ново множество от
vm_area_struct структури от данни заедно с техни собствени mm_struct структури от данни и с page таблиците на клонирания процес. В този
момент все още не се копира никаква част от виртуалната памет на процеса. Това би била доста трудна и продължителна работа, тъй като една част
от тази виртуална памет ще е във физическата, друга ще бъде в изпълним image , който в момента се изпълнява от процеса, а вероятно ще има и
една част в суап-файла. Вместо това Linux използва техника, наречена "копиране при писане", което означава, че виртуалната памет ще бъде копирана,
когато някои процес се опита да пише в нея. Което осигурява да бъде споделяна от два процеса без проблем. Памет само за четене, както и изпълним код
също могат да бъдат споделяни. За да работи метода "копиране при писане" е нужно page-таблиците на тези области от паметта да са само за четене и
vm_area_struct, които ги описват да са белязани като copy on write. Когато някой от процесите се опита да пише в тази виртуална памет ще се получи page fault
и ядрото ще предприеме необходимото.
7. Времена и таймери
Кернела пази записи за времето на създаване всеки процес, както и процесорното време, което той консумира през “живота” си.
При всеки такт на часовника кернела опреснява количеството време в мигове, които текущият процес е прекарал в системен и в потребителски режим.
В допълнение на тези сметки за времето, Linux поддържа и специфични таймери на интервалите за всеки процес.
Един процес може да използва тези таймери, за да си изпраща най-различни сигнали всеки път, щом те изтекат. Поддържат
се три вида таймери за интервали:
Реални
Таймерът работи в реално време, и когато изтече, на процеса се изпраща сигнал SIGALRM.
Виртуални
Този таймер работи само когато процесът се изпълнява, а когато таймерът изтече, на процеса се изпраща сигнал SIGVTALRM.
Профилни
Този таймер работи както когато процесът се изпълнява, така и когато системата се изпълнява от името на този процес. Изпраща
се сигнал SIGPROF когато изтече.
Могат да работят един или повече таймери на интервалите, и Linux пази цялата необходима информация в структурата от данни
task_struct . За стартирането, спирането и настройването на определени техни стойности може да бъдат правени системни обръщения. Виртуалните и
профилните таймери се манипулират по същия начин.
При всеки такт на часовника интервалните таймери на текущия процес се намаляват с единица, и ако са изтекли, се изпраща
съответния сигнал.
Реалните интервални таймери са малко по-различни и за тях Linux използва механизъм, който е описан в главата за кернела.
Всеки процес има своя собствена структура от данни timer_list , и когато работи истинския интервален таймер, той влиза в списъка на системния таймер.
Когато таймерът изтече, манипулаторът му го отстранява от списъка и извиква манипулатора на интервалния таймер.
Това генерира сигнал SIGALRM и рестартира интервалния таймер, вкарвайки го отново в списъка на системния таймер.
8. Изпълнение на програми
В Linux , както и в UnixTM, програмите и командите обикновено се изпълняват от команден интерпретатор.
Командният интерпретатор е потребителски процес като всеки друг и се нарича шел.
За Linux има много шелове, а сред най-популярните са sh, bash и tcsh. С изключение на няколко вградени команди като
cd и pwd , всяка команда е изпълним двоичен файл. При въвеждането на всяка команда шелът претърсва директориите на процеса, съдържащи
се в променливата на обкръжението PATH за изпълним файл със съвпадащо име. Ako такъв е открит той се зарежда и изпълнява.
Изпълнимият файл може да бъде в множество формати, или дори да бъде скрипт файл. Скриптовете трябва да бъдат разпознати,
и тогава се стартира необходимия интерпретатор, който да ги управлява; например /bin/sh интерпретира шел скриптове. Изпълнимите обектни файлове
съдържат изпълним код и данни на едно място, заедно с достатъчно информация, която да позволи на операционната система да ги зареди в паметта
и да ги изпълни. Най-често използваният от Linux обектен формат е ELF, но теоретично Linux е достатъчно гъвкав, за да може да се справи с почти
всеки обектен формат.
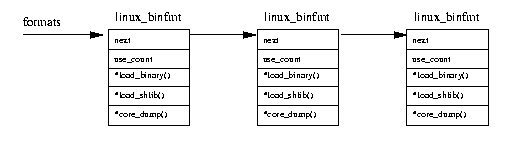
Фигура 4.3. Регистрирани двоични формати
Както и файловите системи, двоичните формати, поддържани от Linux са или вградени в кернела по време на компилирането
му, или могат да бъдат зареждани като модули. Кернелът има списък с поддържаните файлови формати, и когато бъде направен опит да се изпълни
даден файл, се опитва поред всеки двоичен формат, докато някой сработи.
Най-често използваните формати в Linux са a.out и ELF . Няма нужда изпълнимите файлове да бъдат изцяло зареждани
в паметта – за целта се използва техника, наречена “ зареждане при поискване ”. Когато някоя част от изпълнимия файл се използва от процес, тя се зарежда
в паметта. Неизползваните части от файла просто се отстраняват от паметта.
8.1. ELF
Обектният файлов формат ELF (Executable and Linkable Format) , разработен от Unix System Laboratories , се е утвърдил като
най-широко използван в Linux. Въпреки че има малка разлика в производителността, ако го сравним с формати като ECOFF и a.out , ELF се смята
за по-гъвкав. Изпълнимите файлове ELF съдържат изпълним код, понякога като текст, а също и данни. Таблици вътре в изпълнимия файл описват как
програмата би трябвало да се разположи в паметта заделена за процеса. Статично свързаните имиджи се изграждат от linker или свързващ редактор в един
имидж, съдържащ всички данни и код, които са необходими за да се стартира имиджа.
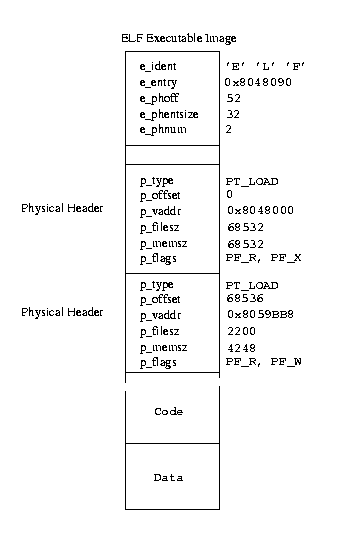
Фигура 4.4. Изпълнимият файлов формат ELF
Фигура 4.4 показва статично свързан ELF изпълним файл.
Това е проста С програма, която изписва “ hello world, и след това излиза. В началото тя е описана като ELF файл с два
физически хедъра (e_phnum е 2), започващи на 52 байта (e_phoff) от началото на файла. Първият физически хедър описва изпълнимия код във файла.
Той започва от виртуален адрес 0x8048000 и е дълъг 65532 байта. Това е така, защото файлът е статично свързан и съдържа целия библиотечен код
за обръщението printf() , при което се извежда “ hello world. Първата инструкция за програмата не е в началото на имиджа, а на адрес 0x8048090 (e_entry).
Кодът започва веднага след втория физически хедър. Този хедър описва данните за програмата и ще бъде зареден във виртуалната памет на адрес 0x8059BB8.
Тези данни са както за запис, така и за четене. Ще забележите, че размера на данните във файла е 2200 байта (p_filesz), а паметта е 4248 байта. Това е защото
първите 2200 байта съдържат първоначално инициализираните данни, а останалите 2048 данните, които ще бъдат инициализирани от програмния код.
Когато Linux зареди ELF изпълним файл във виртуалното адресно пространство на даден процес, той всъщност не зарежда
файла. Настройват се структурите от данни на виртуалната памет, дървото vm_area_struct на процеса и неговите page таблици. Когато програмата
бъде изпълнена, грешките в страниците ще направят така, че програмния код и данни да бъдат извлечени във физическата памет. Неизползваните части
от програмата никога няма да бъдат заредени в паметта.
ЕLF поделени библиотеки
Един динамично свързан файл, от друга страна, не съдържа целия код и данни, необходими за изпълнението му.
Някои от тях се съдържат поделени библиотеки, които са свързани с файла по време на създаването му. Таблиците на ЕLF поделените
библиотеки също се използват от динамичния линкър поделената библиотека се свързва с файла при изпълнение. Linux използва няколко
динамични линкъра - ld.so.1 , libc.so.1 и ld-linux.so.1 , които могат да бъдат намерени в /lib. Без динамично свързване на библиотеки ще са необходими
отделни копия на тези библиотеки за различните процеси, което ще отнема повече дисково пространство и виртуална памет.
8.2. Скрипт файлове
Скриптовете са изпълними файлове, които имат нужда от интерпретатор, който да ги стартира. В Linux има голямо
разнообразие интерпретатори; например wish , perl и командни шелове като tcsh . Linux използва стандартната UnixTM конвенция
за поставянето на името на интерпретатора в първия ред на скрипта. По този начин един типичен скрипт започва така:
#!/usr/bin/wish
Двоичният изпълнител на скриптове се опитва да намери необходимия за скрипта интерпретатор.
Той прави това като опита да отвори изпълнимия файл, упоменат в първия ред на скрипта. Ако успее, има указател към
неговия VFS i-възел и може да продължи нататък, и да интерпретира скрипта. Името на скрипта става аргумент нула (първия аргумент) и всички
други аргументи минават с една позиция нагоре (оригиналният първи аргумент става нов втори и т.н.) Зареждането на интерпретатора става
по същия начин, както Linux зарежда и всички останали изпълними файлове. Linux опитва всеки един двоичен формат, докато някой не се
окаже подходящ. Това означава, че на теория бихте могли да съберете на едно място няколко интерпретатора и двоични формата, като по този
начин направите манипулатора на Linux-изпълнимия код много гъвкаво парче софтуер.